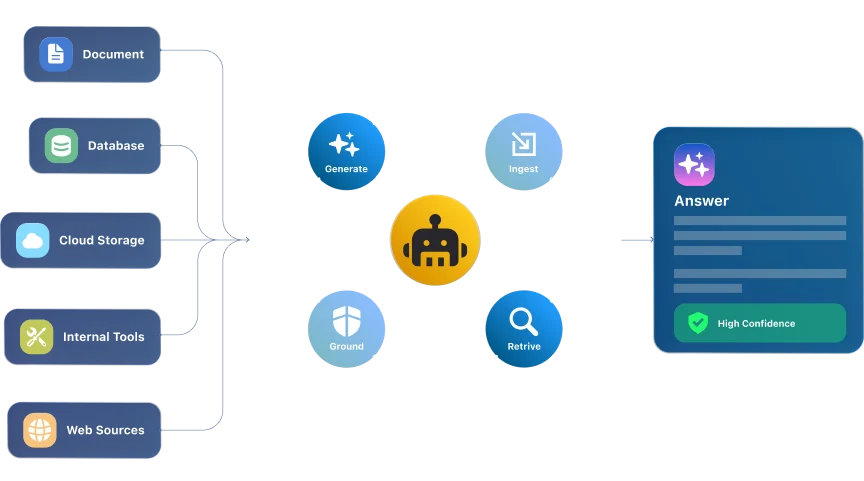
At Idea Maker, we architect and build the complete Retrieval-Augmented Generation pipelines from data ingestion to response generation that turn scattered business knowledge into reliable AI outputs. Designed for production from day one, our RAG development services are built around accuracy, context, and real-world use. Get a RAG system that reduces hallucinations and delivers responses your teams can trust for everyday business decisions.
Book a Free Consultation Today!







Implies full-stack, end-to-end capabilities, not just simple apps
At Idea Maker, our RAG development services cover the full lifecycle from early strategy and system design to production deployment and continuous optimization. You don’t have to coordinate multiple vendors or piece together disconnected components. We build, integrate, and refine every layer of the pipeline so your AI systems stay accurate, scalable, and aligned with real business outcomes as they evolve.
Not sure which service you need? Book a free 30-minute scoping call with our RAG consultants!

Don’t build in the dark. Our RAG consulting service offers the expert guidance you need before and during RAG implementation. We review your knowledge sources, user needs, data access patterns, feasibility, and architecture directions to determine the highest ROI RAG use cases. You receive a tailored phased roadmap, covering system scope, retrieval requirements, build/buy/partner analysis, risk areas, and cost estimates.
We design production-ready RAG architectures that balance accuracy, latency, and cost from the start. This includes data flow, embedding model selection, vector database choice (Pinecone, Weaviate, Qdrant, pgvector, Milvus), retrieval logic (hybrid search, reranking), indexing structure, and response orchestration. We plan how each layer works together across knowledge ingestion, vector search, reranking, access control, and model interaction.
Our custom RAG development services offer end-to-end RAG-powered applications like internal knowledge assistants, customer support copilots, or research tools tailored to your workflows. These systems are designed around your data and integrated with your existing environment, with intuitive interfaces, APIs, and access controls that make them usable across teams from day one.
A robust RAG system development depends on how well data moves through the pipeline. That’s where we build the ingestion, cleaning, chunking, metadata tagging, embedding generation, indexing, retrieval, and context assembly layers that power accurate AI responses. Whether it’s documents, databases, or knowledge platforms, we structure your data so retrieval is fast, relevant, and consistently aligned with user queries.
When your knowledge is spread across text, images, tables, scanned documents, charts, and structured records, basic text retrieval is not enough. Our multimodal RAG development services offer RAG systems that can work with different data formats through document parsing, OCR, visual understanding, metadata extraction, and cross-format retrieval. This is ideal for industries where information does not live in plain text alone.
For more complex workflows, our agentic RAG development services offer RAG solutions that can retrieve information, compare sources, trigger tools, follow multi-step workflows, and support task execution. This includes AI agents for research, customer operations, compliance review, sales enablement, knowledge management, or internal process automation.
We connect RAG capabilities to your existing systems, including CRMs, ERPs, databases, cloud storage, document repositories, support platforms, and internal dashboards. Our RAG integration services cover APIs, authentication, permissions, data sync, and workflow embedding, so your RAG system becomes part of your existing software environment instead of a separate AI tool.
We assess your RG system for retrieval evaluation, answer quality checks, hallucination testing, latency review, and prompt refinement. For that, we use techniques like RAGAS, custom eval suites, human-in-the-loop review, and observability. After identifying the issues, our team improves chunking, metadata, reranking, context windows, and retrieval strategies.
As your documents change, usage grows, and requirements evolve, we provide managed support to keep your RAG system performing at its best. Our team performs knowledge base updates, retrieval monitoring, embedding refreshes, performance tuning, issue resolution, and system scaling. Your RAG environment stays accurate, efficient, and cost-conscious over time.
Built for These Use Cases
RAG is most effective when AI needs to deliver answers based on trusted, evolving, and business-specific information, rather than relying solely on general model training. The use cases below highlight where access to real data, source-backed context, and accurate retrieval make RAG a stronger fit than traditional chatbots, static search tools, or rule-based systems.
See a use case that fits your team? Book a 30-minute free fit assessment call with Idea Maker today!
Internal knowledge is rarely organized the way employees need it. Policies are stored in one place, SOPs in another, and technical details are located elsewhere. With RAG, companies can build enterprise knowledge assistants that bring this information together into a single, searchable layer. Teams get direct, context-aware answers instead of digging through documents or relying on incomplete internal search.
Support teams often rely on multiple knowledge bases during live interactions. RAG enables companies to build customer support copilots that surface the right troubleshooting step, product detail, or policy while the interaction is happening. Human agents stay focused on the customer, while the system brings forward the exact context needed to respond accurately.
Analysts, consultants, legal teams, and technical researchers use RAG systems to review large volumes of reports, contracts, papers, meeting notes, and market documents. Traditional search stops at matching files, while research analysis RAG tools help connect evidence across documents without losing traceability. Researchers retrieve relevant passages, compare context, and produce grounded summaries that still trace back to source material.
Generic chatbots break down quickly in industries where terminology, compliance rules, workflows, and product logic matter. Healthcare, finance, insurance, education, logistics, and SaaS companies often need chatbots that understand their terminology, policies, workflows, and compliance boundaries. Leveraging RAG companies can build compliance-aware chatbots, internal advisory bots, and domain-trained assistants without retraining a model from scratch.
Revenue teams sit on valuable context inside CRM notes, call transcripts, proposals, product sheets, pricing rules, competitor research, and customer history. RAG helps turn that scattered data and helps teams prepare account briefs, personalize outreach, answer buyer questions, and identify next-best actions from existing data. RAG-powered tools like sales intelligence platforms, deal support assistants, and revenue analytics copilots beat generic AI assistants because the output is grounded in the current deal context, rather than broad sales advice.
Expert Strategic Guidance and Full-Stack Model Deployment
AI systems often break at the point where they need real business knowledge. Answers miss key details, pull from the wrong sources, or reflect outdated information. Teams struggle to find what they need, and users stop trusting the system. Production RAG addresses these gaps by connecting AI to the right data, retrieving it accurately, and making responses dependable in production workflows.
Generic AI systems often provide an inaccurate answer confidently, even when they lack the right context. In support, sales, legal, HR, or operations, which creates risk fast. RAG gives the model a source of truth by connecting responses to approved policies, product documentation, knowledge bases, and internal records instead of leaving it to guess.
Critical business information is usually hidden across PDFs, CRMs, databases, wikis, shared drives, ticketing tools, and old documentation. Employees waste time searching, switching tools, or asking the same questions repeatedly. RAG helps bring that scattered knowledge into a connected retrieval layer, so teams can ask one question and get an answer shaped by the right internal context.
AI becomes risky when it answers from old training data, outdated policies, or static documentation snapshots. Businesses change pricing, product rules, compliance language, and internal processes constantly. RAG helps keep responses aligned with current knowledge by retrieving from updated sources without retraining the entire model.
Many AI systems fail because they retrieve the wrong chunks, miss important context, or overload the model with irrelevant information. The answer may look polished, but the foundation is weak. Production RAG improves this through better chunking, metadata, indexing, reranking, and retrieval logic built around how users actually ask questions.
For regulated teams, “the AI said so” is not a defensible answer. They need to know which source was used, who had access, and whether the response followed internal rules. RAG supports controlled access, source traceability, audit-friendly outputs, and permission-aware retrieval across sensitive documents, customer data, and compliance knowledge.
A RAG demo can look impressive with a small dataset and simple queries. Problems appear when usage grows, documents change, permissions matter, latency increases, and edge cases multiply. Production RAG solves for the operational layer: scalable pipelines, monitoring, evaluation, updates, fallback handling, and infrastructure that can support real users.
Skip ahead if you already know what RAG is, but if you need a 90-second primer before signing off, here's RAG in plain terms.
RAG is an AI architecture that lets a language model retrieve relevant information before generating an answer. Instead of asking the model to respond from generic memory, the system searches connected sources such as documents, databases, knowledge bases, policies, support content, or internal wikis. Then it uses that retrieved context to produce a more accurate response with citations.
The architecture has three main layers:

Retrieval is where the system finds the right information. It searches connected knowledge sources, identifies relevant passages, and filters results based on meaning, metadata, permissions, or business rules. The goal is simply to pull the right information before the model starts answering.
The retrieved content is then added as context for the model. This step gives the AI the facts, source material, and business-specific details it needs to answer properly. Good augmentation also controls what information is passed forward, so the model receives useful context instead of a messy dump of documents.
The language model uses the retrieved context to produce a clear answer, summary, recommendation, or response. Unlike a standard chatbot, the output is grounded in your own knowledge base. That makes RAG especially useful for enterprise search, customer support, internal assistants, research tools, and domain-specific AI applications.
| Dimension | RAG | Fine-Tuning | Generic LLM (Prompt-only)> |
| Best for | Answers grounded in your data, with citations | Adapting model style, format, or domain language | General-purpose tasks; no proprietary data needed |
| Data freshness | Live — updates without retraining | Frozen at training time | Frozen at training cutoff |
| Source attribution | Yes — citations to source docs | No native attribution | No |
| Setup time | Weeks to months | Months + ongoing retraining | Days |
| Ongoing cost | Storage + retrieval + inference | Retraining cycles + inference | Inference only |
| Hallucination risk | Low when retrieval is well-engineered | Moderate | High on out-of-domain queries |
| Compliance fit | Strong — auditable trail | Weaker — opaque weights | Weakest — no provenance |
| Engineering complexity | Moderate to high | High | Low |
Fine-tuning, prompt engineering, and traditional LLM deployments all solve different parts of the enterprise AI puzzle. RAG becomes relevant when the main challenge is access to accurate, current, and business-specific knowledge. Choosing the wrong approach can lead to slow rebuilds, inaccurate answers, or unnecessary engineering spend. Our comparison below offers clarity on how each option handles data, control, updates, and production risk.
In practice, the highest-performing systems often combine approaches. Fine-tuned models inside a RAG pipeline, or prompt-engineered LLMs with light retrieval. The right architecture depends on your data, your accuracy requirements, and your operational tolerance for retraining cycles.
Diverse Sectors, Custom Solutions
RAG implementations vary by industry because every sector has different data sources, risk levels, compliance requirements, and accuracy expectations. At Idea Maker, we have worked across industries where answers must be accurate, traceable, and grounded in the relevant data. Each implementation is tailored to your sector’s knowledge sources, compliance requirements, access controls, and accuracy thresholds.
Looking to build a RAG system tailored to your industry? Let’s explore what it could look like for your data.
Document retrieval across regulatory filings, research, compliance manuals, and CRM data with full audit trails.
RAG over clinical guidelines, medical records, and research literature designed for HIPAA-aligned data handling and citation accuracy.
Case law search, contract analysis, and regulatory monitoring with verifiable citations to source documents.
Product documentation assistants, customer support copilots, and engineering knowledge tools for fast-moving codebases and APIs.
Product catalog Q&A, internal merchandising tools, and customer-facing assistants grounded in real inventory and policy data.
Technical documentation retrieval across schematics, manuals, SOPs, and incident histories, including multimodal content.
Curriculum assistants, research tools, and student support copilots are grounded in institutional content and learning materials.
Cross-functional internal copilots for HR, IT, finance, and ops teams drowning in policy docs and historical tickets.
Tech Stack
At Idea Maker, we are not locked into one vendor, model, database, or framework. Our team has worked across modern models, vector databases, orchestration frameworks, cloud platforms, and deployment setups. That’s why we choose the tech stack that best fits your use case instead of forcing a preset technology path.

How It Works
Production RAG takes more than connecting a model to a document folder. The real work happens in how the knowledge is prepared, how retrieval is designed, and how answers are tested before real users depend on them. At Idea Maker, our custom RAG development process keeps every stage tied to a practical deliverable, so the build moves with clarity instead of guesswork.
Ready to take your RAG system from idea to production? Partner with us to build it right from day one!
We begin by understanding what the RAG system needs to answer, who will use it, and which knowledge sources it should trust. Our team reviews your data sources, user workflows, accuracy expectations, security needs, and existing infrastructure. The goal is to confirm whether RAG is the right architecture or whether fine-tuning, prompt engineering, or another AI approach fits better. In 1–2 weeks, you will receive a feasibility memo, refined KPIs, recommended direction, project scope, and a clear go/no-go decision.
Once the direction is clear, we turn the concept into a buildable system design in 1–2 weeks. This includes mapping data sources, retrieval paths, chunking strategy, embedding approach, vector database requirements, evaluation setup, and integration touchpoints. You get a detailed architecture document, milestone plan, and development roadmap that gives both technical and business teams a shared execution path.
RAG quality depends heavily on the knowledge layer. We clean, parse, classify, chunk, tag, embed, and index your content so the system can retrieve the right context later. This stage takes around 2–4 weeks and turns scattered files and records into a structured, searchable knowledge base that can support accurate answers instead of noisy, incomplete retrieval.
Once the knowledge foundation is ready, we move into RAG system development, building the working application around it. That includes an internal assistant, customer support copilot, research tool, enterprise search interface, or domain-specific chatbot. We develop the backend, APIs, retrieval layer, prompt logic, user interface, and source citation behavior needed for a complete product in 3–6 weeks.
After each build, our SQAs thoroughly evaluate retrieval accuracy, answer quality, hallucination risk, latency, permissions, citation reliability, and edge cases. Weak spots are refined in 2–3 weeks through better chunking, metadata, retrieval logic, reranking, and prompt structure before the system moves into production.
Finally, we deploy your RAG system for real users, with the monitoring, access controls, analytics, and documentation needed to support daily business use in 2 weeks. After launch, we define a 30/60/90-day optimization plan to refine retrieval quality, update knowledge sources, monitor usage, and improve performance.
Client Success Stories

Idea Maker has done an amazing job of delivering and responding to our needs.

The team was very responsive and easy to work with. They are professional, talented, and experienced team. They were able to meet all our requirements.

Idea Maker is distinguished for their personalized collaboration and white glove services. The team is dependable and reliable, sticking to the project's plan, offering feedback, and pushing back on the right things.

The way they understand the requirements we present to them is fairly solid. Both in terms of bringing their own interpretation in nailing the requirements and their design sense. By the time we launched, I had gotten significantly more value from our collaboration than what we had discussed in the original specs.

This is a boutique development firm where the Founder is directly involved with the project and the primary contact. This is unlike many development firms where you are simply handed off to developers that are not stakeholders. This is an important distinction that results in much better project accountability.

I have never had a site like this built before. I felt that Idea Maker and Tom had built numerous sites like this, and they were pros.

Idea Maker's portfolio is what drew us in. Their design style was in alignment with what we were after. We had initial consultations with 3 companies that we had narrowed it down to. Once we had our initial meeting with Tom at Idea Maker we knew we had the right choice to make. Their communication style works well for us.

Their customer service is excellent — they’re incredibly accessible and available, which I appreciate. Furthermore, they have enough experience and bandwidth to fulfill all my needs. They’re one of the best vendors I’ve worked with.
Our Case Studies

AI-Powered SOC2 compliance platform with modular framework support

An AI SaaS platform that guides users through compliance documents and builds strategies to meet regulations

Automated system to efficiently process and clean bulk data files, incorporating machine learning and Power BI
Enterprise RAG solutions are reviewed by more than the technical team. Security, legal, compliance, GRC, and procurement all need confidence before the system goes live. That’s why at Idea Maker, we build RAG systems with those reviews in mind from the start. So your data protection, access control, documentation, and approval requirements are part of the solution, not last-minute fixes.
Customer Voice
Their customer service is excellent — they’re incredibly accessible and available, which I appreciate. Furthermore, they have enough experience and bandwidth to fulfill all my needs. They’re one of the best vendors I’ve worked with.
Aquila Bernard
Coach
Your business decides where data lives and how it moves. We build RAG systems around approved environments, whether that means private cloud, on-premise infrastructure, or controlled access to specific data sources. Sensitive documents, customer records, and internal knowledge are protected with the right permissions, encryption, and access boundaries from the start.
RAG systems often work with customer data, internal policies, financial records, healthcare information, or confidential documents. Our RAG development services align the system with relevant requirements such as HIPAA, GDPR, SOC 2, and internal governance standards. The compliance approach is documented clearly, giving your legal and security teams the evidence they need during review.
At Idea Maker, we understand that enterprise teams need to know where an AI answer came from. That’s why our every RAG system development project includes built-in source citations, activity logs, and clear visibility into retrieved documents. Reviewers can trace the information behind each response in regulated workflows, customer-facing answers, or high-risk business decisions.
We prepare RAG deployments with practical safeguards such as usage limits, content controls, fallback responses, monitoring, and issue handling. Our RAG systems are designed to handle real users, unexpected questions, traffic spikes, sensitive data, and misuse attempts.
Trust. Strategy. Value. Results.
Plenty of companies can promise a RAG solution. We take ownership of what happens when that system meets real data, real users, and real constraints. At Idea Maker, our RAG development services offer the complete end-to-end pipeline where retrieval accuracy, data quality, and ongoing performance matter more than surface-level outputs.
Looking for more than a surface-level RAG build? Partner with us to engineer the full RAG pipeline!
A reliable RAG system depends on far more than a chatbot connected to documents. Our RAG application development approach covers the complete pipeline, including data ingestion, document parsing, embeddings, retrieval logic, response generation, orchestration, evaluation, and observability. Each layer is planned together, so the system works as one product instead of a collection of disconnected AI components.
A demo can look impressive with clean files and friendly questions. Production is where latency, messy documents, permission rules, usage spikes, and edge cases start to matter. We engineer RAG systems for those realities from the beginning, with testing, monitoring, fallback handling, and performance checks built into the development process.
RAG is powerful, but it is not always the right answer. Some projects need fine-tuning. Others only need better prompting, workflow automation, or a simpler search layer. We assess the actual problem first, then recommend the architecture that fits your data, budget, timeline, and business goals.
As a business owner, you need clear visibility before committing to a RAG build. Our team outlines realistic timelines, cost ranges, dependencies, and trade-offs before RAG application development begins so you can make informed decisions. If a use case carries risk, adds unnecessary complexity, or is unlikely to deliver value, we address it directly and guide you toward a more viable approach.
FAQs
Timelines depend on the complexity level. A basic RAG proof of concept usually takes 3–6 weeks, while a production-ready RAG system often takes 8–16 weeks. Enterprise RAG projects can take 4–6 months when they involve multiple data sources, role-based access control, hybrid search, evaluation pipelines, and high-availability deployment.
RAG development typically costs $7,500 to $40,000 for a basic MVP, $15,000 to $150,000 for a medium-scale system, and $120,000 to $500,000+ for an enterprise RAG. The final cost depends on data volume, integrations, security requirements, retrieval complexity, and production infrastructure. We provide pricing ranges early after reviewing your use case and technical requirements.
RAG is usually a better fit when your AI system needs access to current, private, or frequently changing knowledge such as policies, product docs, customer records, reports, or internal wikis. Fine-tuning is better for shaping model behavior, style, or domain patterns, but it does not replace live knowledge retrieval.
We design RAG systems around your security requirements from the start. That may include private cloud or on-premise deployment, role-based access, encryption, audit logs, source traceability, and compliance alignment with frameworks such as HIPAA, GDPR, SOC 2, or internal governance policies.
Yes. RAG is often built for unstructured business knowledge. We can process PDFs, scanned documents, support articles, internal wikis, reports, manuals, policies, and knowledge bases.
After launch, we monitor performance, retrieval quality, usage patterns, errors, latency, and answer accuracy. As your documents and workflows change, we refine the system through knowledge updates, embedding refreshes, retrieval tuning, new integrations, and ongoing optimization.

Idea Maker © 2026 ● All Rights Reserved