Artificial intelligence evolves so quickly that it is no longer confined to a single mode of understanding. It now sees, listens, reads, and interprets simultaneously. This transformation is driven by multimodal AI, which understands and generates not only different types of data (text, images, audio, and video), but also their combination. The market for multimodal AI is projected to be over $6 billion by 2032. This isn’t just a tech upgrade; it’s an inflection point in how companies solve problems, engage customers, and compete. As it becomes more widely implemented, the importance of leaders knowing how and where multimodal AI can bring value to their organization increases.
This article explores multimodal AI examples across various business sectors and examines the tangible impact it’s already making on business performance.
What Is Multimodal AI?
In AI, modality refers to the data types. Multimodal AI is an AI system capable of processing and generating multiple data types, including text, images, audio, and video. Instead of just looking at a data source, multimodal AI can develop a more complete sense of what’s happening in a given situation by incorporating images, sounds, and the written word.
It is like human perception of the world. For example, when a doctor makes a diagnosis about a particular disease, they don’t depend on just one piece of information. What they take into account, then, are wide ranges of authors which cover at the same time:
- A medical report (text)
- X-rays (images)
- Tone of voice (audio)
- Physical symptoms (visual cues)
Multimodal AI replicates this layered reasoning using machine learning, and many of the most impactful multimodal AI examples mirror this process.
Multimodal vs. Unimodal AI
The primary difference between multimodal AI and unimodal AI is the number of data sources that they can process.
Multimodal AI processes multiple types of data when training and inferring. They address more complicated situations and provide richer, more accurate, and more human-like understanding and generation of information than their traditional counterparts. For instance, given an image of a dish, Gemini can render its recipe in textual form and vice versa.
Unimodal AI is trained on a particular type of input, so a chatbot trained on only text or a vision model trained on images would not generalize well to other types of input. While this kind of AI excels in specific tasks, it doesn’t have the contextual depth to make complex decisions.
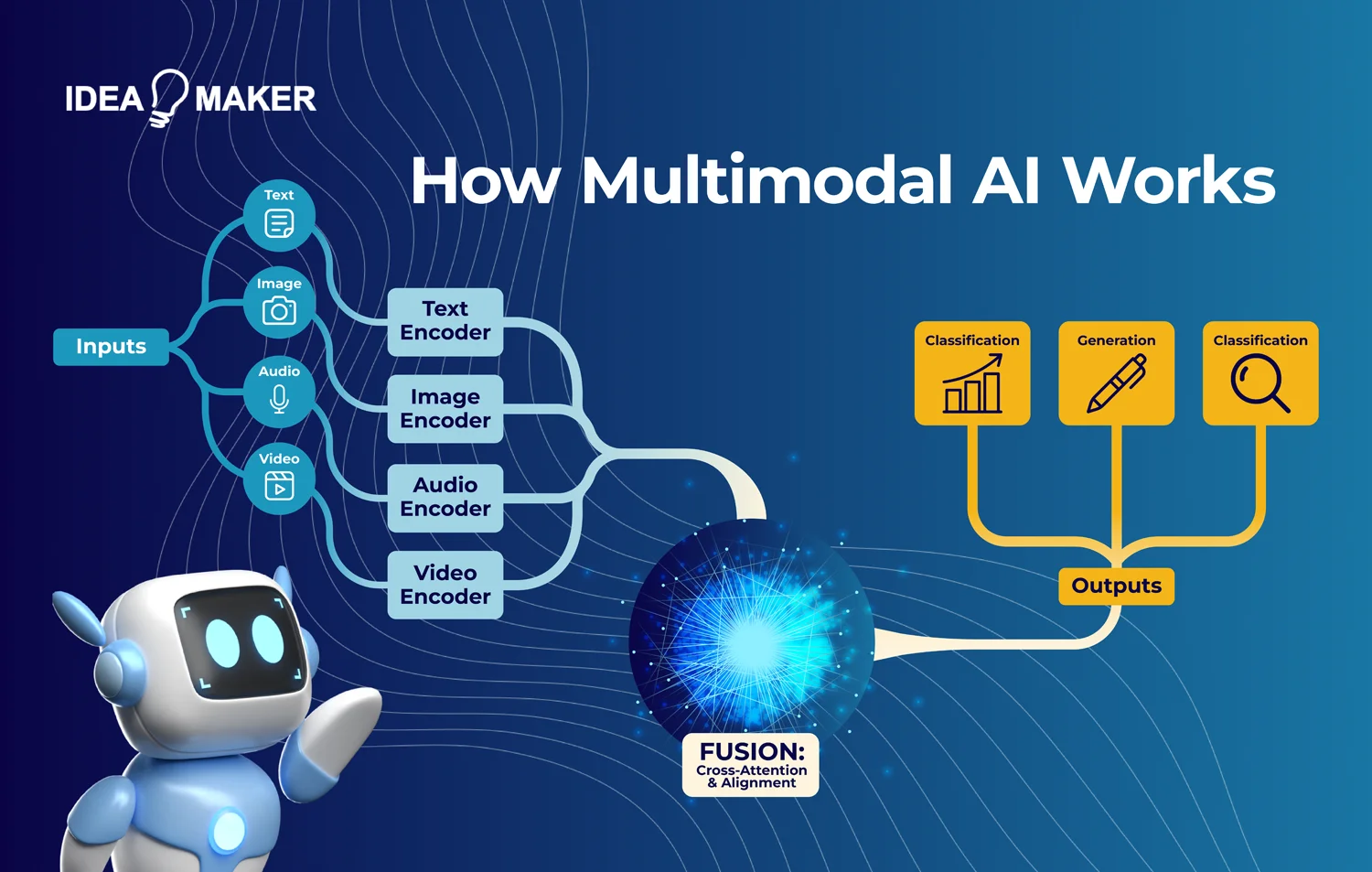
How It Works
Multimodal models are built using domain-specific transformers for encoding the input modality data into a single, homogeneous representation, with very efficient cross-attention mechanisms.
A multimodal AI system contains three main components:
- Input Encoding: Each modality (e.g., text, image) is first processed by its respective encoder (e.g., a vision transformer for images, a language model for text).
- Fusion Layer: Encoded data streams are put through attention mechanisms to align and merge them into a coherent context-aware representation.
- Prediction Layer: Finally, the fused representation, along with task decomposition, is then passed to downstream tasks such as classification, generation, or retrieval.
- Early fusion (data is combined at the input level) or late fusion (individual processing experiences are merged).
Some models use early fusion by combining data at the input stage, while others merge after individual processing using late fusion.
Key Modalities
The majority of modern multimodal systems are based on a combination of the following:
- Text: Unprocessed natural language input (e.g., document, instruction, or query)
- Image: Visual data such as photos, scans, diagrams, or video frames.
- Audio: Spoken language, ambient sounds, tone, and inflection.
- Video: Time-series data with spatial and temporal dimensions.
- Sensor Data: Inputs from IoT Devices, LiDAR, GPS, or Biometric sensors.
In the following sections, you’ll explore practical examples of multimodal AI in action, along with the measurable impact it’s creating for businesses and industries across various domains.
Multimodal AI Examples in Healthcare
Radiology + Clinical Notes Fusion for Diagnosis
Medical images alone often lack context. Multimodal AI uses radiology scans combined with EHR data such as lab results and physician notes to enhance diagnostic accuracy for conditions like pneumonia, lung cancer, cardiovascular disease, and breast cancer. Multimodal AI systems can outperform single-source AI approaches in diagnostic performance by 6% to 33%.
For instance, Microsoft’s Project InnerEye and IBM Watson Health have explored image-text fusion to support radiologists in clinical decision-making.
Patient Monitoring via Audio-Visual Signals
Rather than depending solely on vital signs, the multimodal systems analyze video and audio to detect issues earlier. Video tracks changes in posture or facial expression, while audio captures variations in breathing or episodes of coughing. Paired with sensor data, this approach provides a real-time alert to conditions such as respiratory distress.
Solutions such as Biofourmis’ AI-driven monitoring platform and Philips IntelliVue Guardian integrate multimodal inputs to deliver proactive patient care.
Medical Question Answering with Image-Text Models
Multimodal models can also use the patient record to interpret medical images for clinical querying. A doctor, for instance, could upload an X-ray and inquire about how it relates to a patient’s medical history. Such tools enable telemedicine and aid physicians by associating imaging results with textual information.
Tools like Google’s Med-PaLM Multimodal (M) are advancing in this space to facilitate clinicians to query imaging alongside notes.
Applications in Autonomous Vehicles
Sensor Fusion: Combining Lidar, Camera, and GPS Information
LiDAR supplies depth, cameras provide visual context, and GPS records position. Individually, all three have drawbacks, but when multimodal AI combines them, vehicles can see their surroundings completely and reliably. Enhancing object detection and lane keeping, especially in adverse conditions.
Waymo and Tesla Autopilot leverage multimodal sensor fusion for safer navigation systems.
Real-Time Decision Making Under Dynamic Environments
Safe driving requires fast reactions. AI in the automotive industry combines radar with video feeds and traffic lights. Multimodal AI allows cars to predict unexpected dangers like a pedestrian stepping into the street or another car suddenly swerving and respond instantly. NVIDIA’s Drive platform enables real-time decision-making using multimodal inputs to power autonomous fleets.
Predictive Maintenance via Multimodal Telemetry
Beyond navigation, multimodal AI looks at the health of the vehicle. Models can identify anomalies and predict failures by observing data on vibration readings, engine noise, and on-board sensor readings. This facilitates predictive maintenance and aids in extended vehicle longevity by minimizing downtime.
Multichannel AI for Retail / E-commerce
Visual Search + Text-intent Matching
Multimodal AI enhances product discovery by combining image recognition with natural language queries. Instead of endless scrolling, customers can combine text and visuals in a single query, such as “red sneakers under $80.” Multimodal LLM matches both style and price for a seamless product discovery.
Interestingly, the retail and e-commerce sector is leveraging this technology at a rapid pace, with the market for multimodal AI in this industry expected to grow at a 34.60% CAGR through 2030.
AR Shopping with Real-Time Visual + Audio Guidance
In augmented reality shopping apps, multimodal AI blends visual recognition with voice guidance. Customers can preview products in their space and receive spoken recommendations, creating a more interactive buying experience.
Sentiment Analysis of Customers from both Voice and Facial Hints
Customer service platforms leverage multimodal AI to assess the level of satisfaction in real time. Voice tone, facial expressions, and chat data are analyzed together, helping retailers adapt responses and improve service outcomes.
Media and Entertainment Use Cases
Video Captioning and Summarization
AI models can watch and listen to video, and then generate accurate captions and concise summaries. Instead of manually tagging or transcribing hours of footage, production teams can quickly create searchable highlights and accessible content for different audiences.
Music Generation from Text Prompts
Text-to-music systems rely on multimodal AI to convert written prompts into fresh compositions. A term like “ambient piano with soft rain sounds” can produce a track that corresponds to mood and genre. This opens up new opportunities for creators and customized soundscapes.
Deepfake Detection through Audio-Visual Alignment
The rise of manipulated media has made detection critical. But multimodal AI addresses this issue by examining the correlation between audio tracks, lip movements, facial gestures, and visual references to safeguard the political and entertainment content. Studies show that multimodal systems can achieve over 90% detection accuracy on benchmark datasets like DFDC (DeepFake Detection Challenge), compared to ~75% for unimodal systems.
Industrial and Manufacturing Implementations
VI with Textual WOs
Computer vision systems identify defects in products, but multimodal AI adds an additional layer by mapping those findings to textual work orders or maintenance logs to enhance the quality standards.
Audio-Vibration Analysis for Equipment Anomalies
A failing machine rarely shows one warning sign. By listening to acoustic signals while also tracking vibration data, multimodal AI can detect subtle deviations operators might miss. That means problems can be addressed before they shut down an entire line.
Safety Monitoring with Multi-Sensor Feeds
A multimodal monitoring leverages data from all sensors, including cameras, wearables, and environmental sensors, to provide a full view of worker safety. For instance, AI could identify if a worker isn’t wearing protective gear or if toxic gases are in the air by sending alert notifications.
AI-Powered Education Tools
Multimodal Tutoring Systems: Video + Text Feedback
AI-powered tutoring integrates pre-recorded lectures with interactive Q&A. A student watching a video can pause, type a question, and receive AI-generated explanations that tie directly back to what was just taught. According to an experiment, a multimodal AI education system enhances the accuracy rate by 23.6% compared to the traditional evaluation method.
Emotion Recognition in Student Engagement
Online classes often make it harder for teachers to gauge participation. By interpreting facial expressions, voice inflection, and behavior within interactions, multimodal AI can even infer the level of student engagement.
Translation between Sign Languages based on Image and Motion Data
For universality, multi-modal AI could translate sign language into text or speech. These systems analyze video footage of hand gestures and body movements to facilitate communication for hearing-impaired students.
Common Multimodal AI Models and Architectures
- GPT-4o (OpenAI): Process text, images, audio, and video in real-time for coherent human-AI interaction across all four modalities.
- CLIP (OpenAI): Connects text with images for user-friendly search, tagging, and zero-shot classification without task-specific training.
- Flamingo (DeepMind): Designed for few-shot learning, it integrates vision and language to comprehend the images or videos with very few examples.
- PaLM-E (Google): Multimodal reasoning for robotics, which connects visual perception with text to direct physical action.
- Kosmos-2 (Microsoft): Combines vision and language for better context, comprehends text paired with a visual environment (useful for reasoning).
- ImageBind (Meta): Aligns six modalities (text, image, audio, depth, thermal, motion) for richer cross-sensory AI applications.
- LLaVA: Combines LLaMA with vision encoders for effective Visual Question Answering (VQA) and conversational image understanding.
- Gemini (Google DeepMind): Constructed as a multimodal base model that combines reasoning, planning, and memory in both text, image, and code.
- Claude 3 (Anthropic): Emphasizes safe, multimodal comprehension on powerful text+image analysis designed for enterprise use.
- DALL·E 3 (OpenAI): Produces detailed, prompt-accurate images from text, embedded into various workflows, such as design and marketing.
Key Benefits of Multimodal AI Systems
- Greater Context Understanding: Multimodal AI reduces the misinterpretations caused by single-mode models as it interprets information in the way humans do.
- Greater Degree of Precision and Trust: Cross-referencing multiple inputs (e.g., audio + visual) improves decision-making, whether in diagnosing medical scans or detecting fraud.
- Natural Human-AI Interaction: Users can interact with multimodal AI through speech, gesture, or image, and need not be restricted to text-based inputs.
- Enhanced Personalization: Systems can adapt to users better by considering emotional tone, facial cues, and spoken intent, not just written words.
- Cross-Domain Versatility: In fields like healthcare, manufacturing, entertainment, and education, multimodal AI enables solutions that single-modality setups alone don't take as far.
- Better Accessibility: Solutions such as sign language recognition, picture-to-text, and voice-based assist make technology more accessible for the differently abled users.
- Real-time Insights on Multi-stream Data: Multimodal analysis can treat multiple streams of data (processed in real-time) to infer environmental safety, such as in financial trading, timely strategies, and safety monitoring.
Challenges and Perspectives of Multimodal AI

Data Alignment and Synchronization
Various inputs like MRI scans, a doctor’s notes, and a patient’s speech rarely arrive in a neat format or timeline. Aligning them is critical because even minor misalignment can lead to false insights or missed patterns.
Model Complexity and Resource Demand
Multi-modal AI requires larger models that can handle multiple data streams simultaneously. This spikes up training costs, inference latency, and hardware requirements, making scalability a real challenge for startups and enterprises of all sizes. For example, training a complex multimodal AI model can cost up to $78,352,034 or more, depending on the scope and resources involved.
Bias Propagation Across Modalities
Bias isn’t limited to just text and images; it gets worse when modalities come together. A model built on biased medical notes might read scans differently for some groups and could result in skewed results. Research shows that bias from one modality can propagate, leading to bias amplification in multimodal systems up to 22% of the time.
Evaluation Metrics for Multimodal Systems
Traditional benchmarks do not offer the capability to evaluate multimodal systems. Accuracy in one modality doesn’t guarantee overall reliability. The fact is, there is no standard evaluation of these models, which makes it harder to compare models or validate safety.
Future Trends in Multimodal AI Development
Unified Multimodal Foundation Models (e.g., GPT-4V, Gemini)
The rise of unified multimodal models enables a single system to understand and generate across text, vision, audio, and video without needing a separate pipeline. For companies, it lowers the development costs, simplifies integration, and guarantees uniformity between various tasks such as content generation, analysis, and interaction.
Real-time multimodal Interaction in Consumer Products
New consumer tools will merge speech, vision, and contextual awareness in the moment. Think customer support agents that can pick up tone and facial cues, AR devices that overlay instant instructions, or apps that can translate live conversations with context capture. This innovation brings AI a step closer to human levels of natural conversation and redefines customer interaction.
Multi-modal Agents and Embodied AIs
Robotics and self-reliant systems are moving beyond single-sensor processing. By integrating visual and voice inputs with environmental data, embodied AI can make more adaptive and safe decisions, whether it’s a delivery robot navigating crowded streets or an industrial cobot collaborating with workers.
Multimodal Search and Retrieval Systems
Next-generation search will be meaning-driven, not about keywords. Increasingly, users will pose queries to systems like “show me a lecture that describes this chart” or “find design inspirations given this sketch and voice note.” Multimodal retrieval promotes exploration in e-commerce, education, and creative fields for richer knowledge access and personalized recommendations.
How Idea Maker Agency Incorporates Multimodal AI Solutions into Your Business?
At Idea Maker, we turn complex AI into simple, usable tools tailored to your business problems. We develop multimodal AI systems that perceive text, images, speech, and video, and can work together in ways that are relevant to your business. Picture a customer support bot that can listen and watch, or a search tool that can find answers in documents or charts, or even videos in a matter of seconds. We customize solutions using models like GPT-4o, Gemini, or our proprietary frameworks, tailored to meet your specific requirements. It’s always the same goal: Smarter interactions, quicker decisions, more value from your data. With us, AI isn’t merely a tech upgrade; it’s part of how your business scales.
Want to see how multimodal AI can help your business? Book a free consultation today!
FAQ: Key Questions About Multimodal AI
What is the difference between multimodal and cross-modal AI?
Multimodal AI processes and fuses multiple types of inputs, for example, text, images, videos, and audio simultaneously. While cross-modal AI uses one type of input to understand or generate another.
What is the difference between generative AI and multimodal AI?
Generative AI produces outputs like text, images, music, etc. Multimodal AI takes it further by generating and interpreting across different data types together.
Why is modality fusion critical for real-world AI applications?
Fusing inputs like human voice, text, or visuals delivers richer context and therefore more accurate decisions, which leads to greater reliability in real-world tasks.
Can multimodal AI improve model accuracy?
Yes. With aggregated data, models capture more context, which leads to fewer errors and better predictions compared with single-modality AI.
What industries benefit most from multimodal AI?
Industries such as healthcare, retail, finance, manufacturing, and entertainment use multimodal AI in applications including diagnostics, personalization, fraud detection, process automation, and content generation.
How are multimodal models trained and evaluated?
Multimodal models are trained on large datasets of aligned inputs across modalities, and are evaluated using benchmarks that measure accuracy, robustness, and cross-domain reasoning.
Final Thoughts on Multimodal AI Applications
The real value of multimodal AI isn’t in the technology alone, but in what it enables: faster decision-making, richer user interactions, and more reliable insights drawn from diverse data streams. By combining vision, text, speech, and other modalities, companies could discover patterns that a standalone model would miss. With the further maturation of multimodal AI, there's no doubt that it can serve as the bridge between human communication and machine intelligence. But success requires careful integration: matching data, handling model complexity, and implementing ethical safeguards.
Start your journey with Idea Maker’s multimodal AI development service and bring real intelligence to your business operations.